Linear Regression 面试常见考点解析

Linear regression 模型在数据科学岗位日常工作中有广泛应用, 同时它也是数据科学岗位面试的常见考点。在资深面试官眼中的数据科学案例分析面试一文中,我们多次提到面试中非常注重求职者对机器学习基础知识点的深刻理解,而 linear regression 就是最重要的基础知识考点之一。在本文中,我们会结合面试例题给大家精炼梳理 linear regression 相关知识,在随后的系列文章中, 我们会逐一讨论与 linear regression 有紧密联系的 logistic regression, softmax regression 等内容。
如果你想跟我(汪淼Jason) 一起体验数据科学面试流程, 为你指导面试备考或者答题过程中的问题, 欢迎报名参加Techie备受好评的数据科学集训营以及数据科学模拟面试服务. 我会用60+课时的时间,结合90+道数据科学面试真题, 以最高效地方式帮大家梳理数据科学知识体系, 并结合工业界级别的项目训练, 全方位提高大家的综合应用能力以及面试实战技巧. 如果你在数据科学备考或学习过程中有任何问题, 也欢迎扫描下方的二维码或者搜索 TonyCoding20 添加我的微信, 期待和大家的沟通!


1. Linear Regression概念介绍
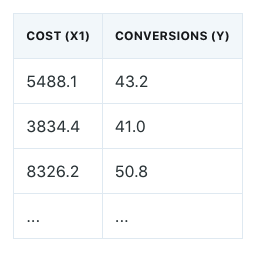
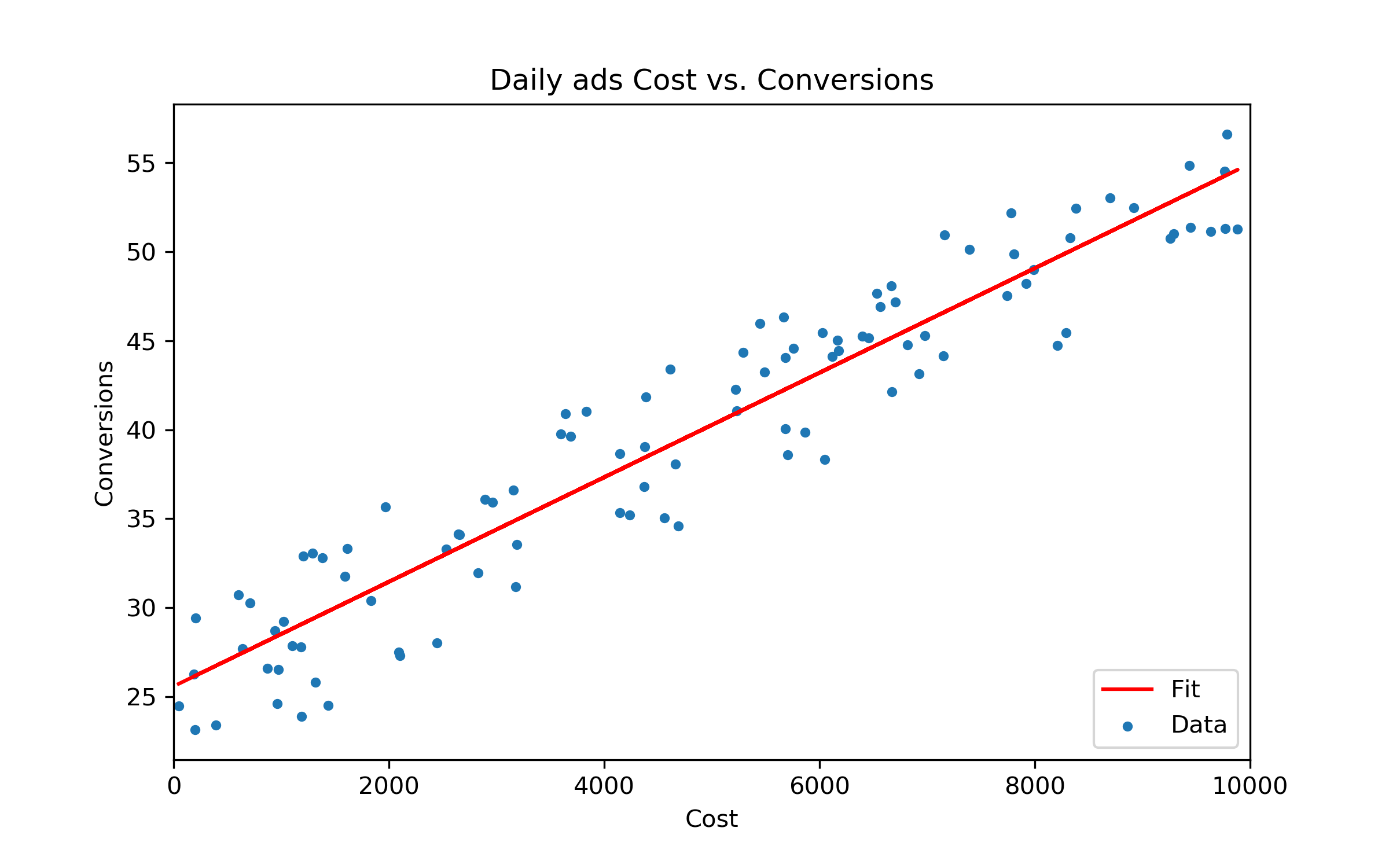
首先,我们用一个非常简单的例子回顾一下 linear regression 的基本概念。以下表格展示了广告 Cost (daily spend on certain ads platform) 和 Conversions (daily conversion volume from this ads platform) 之间的数据关系:
在这里先对一些数据符号进行说明:我们用
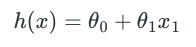
这里
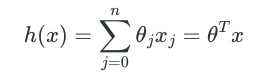
这里 n 是训练数据中 features 的个数(在上面的例子中,n的取值是1)。我们在建模过程中要做的, 就是基于选取的函数
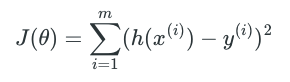
公式中 m 表示全部训练数据的行数。
Notes 1: 我们求解 linear regression 中参数的时候, 并不一定要用 Ordinary Least Squares 这个 estimator。Ordinary Least Squares 只是 Least Squares estimation 中的一种方法,除此之外我们还可以用 Weighted Least Squares (WLS),Generalized Least Squares (GLS) 等方法,我们甚至可以抛弃Least Squares, 改用 Least Absolute Deviations (LAD) 来解决 linear regression问题。因此,大家要注意,在我们选用 linear regression作为 model 之后,我们可以选择任意estimator作为 loss function 的定义方法,Ordinary Least Squares不是唯一方法。
基于上面构造出的 loss function
2. 从概率角度理解OLS Linear Regression
首先,我们给出以下3个概率假设 (probabilistic assumptions) [面试常考点]:
- The dependent variable
- The error term
- (Optional) The error term
Note 2: 在assumption 1中我们对error term的unpredictable random noise的定义也同时默认表示there is no correlation between the independent variables
Note 3: Assumption 3 中对 error term 的 normal distribution assumption 并不是OLS linear regression必需的。只不过 normally distributed error term会使得 OLS 成为 the most efficient linear regression estimator。建议大家在面试时可以直接把这个3个 assumption 都讲出来,在绝大多数情况下面试官是会满意的。 极个别情况下,如果面试官对这个答案提出质疑, 我们可以再进一步讨论第3个 assumption 是 optimal 的。在后文中,我们会默认同时使用这3个 assumptions。
下面我们利用 Maximum Likelihood Estimation 参数估计方法证明:基于上述3个 probabilistic assumptions 得到的 linear regression loss function 与 Ordinary Least Squares estimator 给出的表达式是完全等价的。以下是简化版证明过程[面试常考点]:
Given the assumption
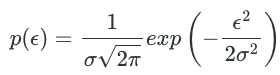
It implies that
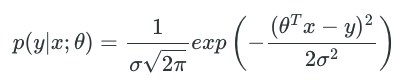
Based on the principal of maximum likelihood estimation, we should choose
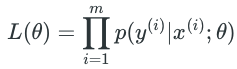
In order to simplify our derivations, we maximize its log likelihood as following:
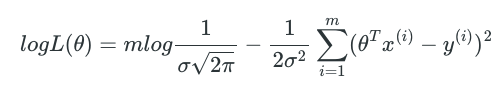
As we can see here, maximizing
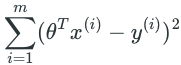
我们可以看到这个结果与利用 Ordinary Least Squares estimator 得到的结果完全一致。注意,这并不表示 OLS 就一定是 linear regression 构造 loss function 最好的方法。它只能说明,我们使用 OLS 构造 loss function, 等价于接受了上述三个assumptions。其中第一个 assumption 对应于 linear form, 无需多言。而接受第2, 3个 assumption,就等价于认为数据中的噪声服从
3. Loss function数值求解
前面我们主要讨论了 linear regression loss function 的构造方法及其合理性。进一步要完成建模过程,我们需要利用数值优化方法求出能使
之前我们构造出了 loss function:
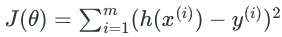
其中
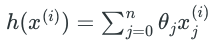
下面我们根据 gradient descent 方法的定义,用如下迭代公式求出能使
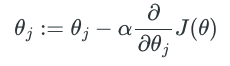
这里我们省略掉中间推导过程, 直接给出结论:
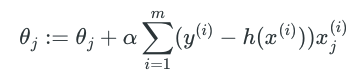
这里
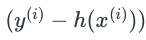
如果这个误差大,那么这一行数据就会对参数
另外,在上面的公式中,每一次迭代做参数更新都是使用全部的训练数据(共m行),这种方法对应于 batch gradient descent。为了加速参数求解过程,我们可以减小每次参数更新时使用的训练数据个数,这些方法对应着 mini-batch gradient descent 或者 stochastic gradient descent。这部分内容在面试中有两种考法, 一种是要求写出参数递推公式,另一种是要求通过编程实现整个参数求解过程。其中编程实现的代码并不长,只需要根据递推公式写出for loop循环即可, 因此关键是对参数递推公式的理解。
4. 总结
Linear regression虽然是最简单的机器学习模型,但在数据科学岗位面试中出现的频率并不低,考点主要涉及 model assumptions 的细节以及 loss function 的相关推导和概念理解。本文从统计机器学习角度把相关常见考点进行了梳理汇总, 至于对 Linear regression 参数估计结果的 statistical hypothesis testing 等数理统计的内容,我们会在后续的文章中继续讨论。最后给大家留一个思考题:
Question: 基于本文中提到的 OLS linear regression 的3个基本假设(包含第三个assumption: the error term follows normal distribution), 我们是否可以认为:linear regression assumes the dependent variable
感兴趣的同学可以在Techie面经论坛与老师们进行讨论。如果大家对于 linear regression 有任何其他问题,也欢迎扫描下方的二维码或者搜索 TonyCoding20 添加我的微信, 期待和大家的沟通!


